RabbitFarm
2019-05-18
There is nothing wrong with use Threads;
Fight me
In a previous article I showed how a significant performance improvement can be made by re-implementing key parts of your Perl code in C++. This was done as an example of improving a brute force computation of the first five perfect numbers. In my writeup of that initial problem I discussed how the best way to improve the speed of that computation was an algorithmic improvement, using well known mathematical relationships to compute the perfect numbers directly and not doing a large scale brute force evaluation of tens of millions of numbers. Still, the fact remains that substantial performance improvements can be made through either one or both of (a) parallelizing the problem and spreading the computation out to run concurrently in pieces and (b) implementing the most computationally intense parts of the code in a compiled language such as C++. (b) was discussed previously, as mentioned above, here we'll take a look at (a). Specifically we'll look at using the perl Threads module. First, though, let's discuss the use of the Threads module.
Threads in Perl
If you want to take full advantage of your hardware and divide computationally intensive tasks across all your CPU cores, and have your code be fully portable, then you need to use Threads. Perhaps the only other option would be to use an MPI implementation, but that introduces significant complexity. Ignoring portability you could you use a fork(), perhaps using one of several modules that makes using fork more convenient. If you choose to ignore having any meaningful benefit to dividing your computationally intense code into different threads of execution than there are modules such as Coro which provide co-operative threads. Co-operative threads share the same CPU so using them for a significant computation would be for cosmetic code organizing purposes only. For non-computational tasks they may provide some benefit beyond the merely cosmetic. For example, when reading from several data sources you can avoid reading them completely in sequence and instead read a little from each until all reads complete. Note that this mediocre sort of threading is as good as you will ever get if you are a Python developer. Well, at least if you use the main CPython implementation of that language. Jython makes full use of the JVM's very nice multi-threading abilities. Most Python developers don't know or care about this limitation because they are mostly just calling wrappers to powerful libraries written in C++ such as TensorFlow. Those libraries of course make full use of C++'s multi-threading as well as GPU APIs.
Now, if you look at the Threads documentation you will find it's written in this extremely hand wringing tone all but begging you not to use them. This is ridiculous and the result of an absurd argument from people that are loud pedantic jerks mean well. The fact is that the Threads module is not implemented in the way an experienced programmer might expect and so it comes with a decent list of use cases which must be avoided. This is mostly because each thread is given its own Perl interpreter. Many all of these cases to avoid are fairly obscure such as "don't use END blocks in a thread". Yeah, sure. Thanks for the heads up.
Indeed I am not aware of any actual horror stories of the Threads module causing trouble in practice. Those that are aware of their limitations either work around them as necessary or write test cases in an effort to bemoan these limitations.
If you're breaking up a tough computation into smaller pieces to take advantage of multiple CPUs Threads provide a simple interface to unleash a lot of processing power. Just read the documentation first and you'll be fine.
The Code
Original code but now threaded

This is the same code as used in the initial problem but with Threads. Getting a rough idea of run time with time we see that it takes about 78 minutes. That is coming down from the original take ~257m. So a little over a 3x speedup.
$ time perl ch-1t.pl
6 28 496 8128 33550336
real 77m58.142s
user 268m17.491s
sys 0m21.845s
We already saw that a substantial speedup is obtained by re-writing the factoring and perfect checking in C++. What if we combined that code with Threads?
Native Library + Threads

$ time perl -Iext -Iext/blib/arch/auto/Perfect ch-1xt.pl
6 28 496 8128 33550336
real 5m40.543s
user 20m6.924s
sys 0m4.594s
Great! We are now able to find the first five perfect numbers with brute force in a little over 5½ minutes. That's a roughly 45x speedup from the original pure (single threaded) perl code.
Notes:
- The number of threads is set to be the number of cores available on my (Late 2012) iMac. A supercomputer it is not.
- The RANGE_SIZE is set to a number that I determined experimentally from a few runs to best reduce the number of wasted evaluations but still put the threads to best use. Remember, these are ithreads and so they don't come cheaply. A new interpreter is created for each one. Angry pedants would scold me for not having creating a thread pool and re-used threads. Also, we're going to end up evaluating numbers that we don't need to because a previously created thread will have found the last perfect number while other threads are still running. I'd argue this is a reasonable tradeoff and when looking for larger and larger perfect numbers not that bad, they do occur very sparsely after all. As a reminder: we're only using this perfect number search as a MacGuffin to try out some different methods. If we were really holding ourselves to the mathematics of perfect numbers we'd have computed them directly and have been done with it!
- It's possible that the perfect numbers would be printed out of numerical order as the threads complete. For the first five this is not really a problem since the first thread created should usually finish well before the last one given the distance between these numbers. Remember, ultimately these threads get executed at the pleasure of your OS and on a busy system unexpected things may happen!
- The time command gives us a decent rough idea of execution time but it is no substitute for closer benchmarking of code if we're really interested in identifying any particular bottleneck.
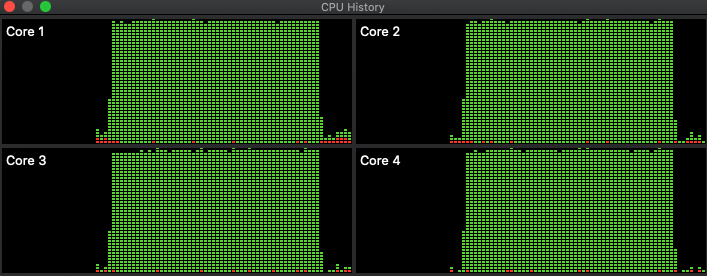
- This is what the core utilization looked before, during, and after a run of ch-1xt.pl. (Ignore the blank to the left which accounts for the time before measuring started) The third and fourth cores seem a but underutilized before being tasked with this computation. You paid for all those cores so use them! use Threads!
Summary
This is the final chapter in a story that started by taking a naive computational approach to identifying perfect numbers and improving it first by re-implementing parts in C++ and then by introducing Threads. Both lead to noteworthy improvement in performance, in fact, a very significant improvement when taken together.
posted at: 13:10 by: Adam Russell | path: /perl | permanent link to this entry